If you’re here and have already read this, you’ll know that AI is already having a devastating impact on the climate; one that is set to get exponentially worse by the end of the decade. Of course, this is for reasons beyond most of our control. But what can *we* do at our level to try and reduce this impact?
As I pointed out in the aforementioned post, one of the most effective ways to reduce AI’s impact is to shift workloads from the US to territories with lower carbon intensity electricity, like France or Sweden (10x less than Virginia, where most US data centres are). But a/. you’re unlikely to get your company to switch cloud providers/data centres and b/. even if you do, there’s no guarantee your AI is running where you’d like it to. For e.g., with Google, even if your company has chosen a low-carbon data centre, Gemini refuses to say whether its workloads are handled there, or elsewhere in the world.
So what can we change? Firstly, by choosing more frugal models; then, by prompting them more frugally. Here we go!
1. Models
Start by avoiding the usual suspects – big tech energy hogs like ChatGPT – and opt for the excellent HuggingChat. Why? It’s made by Hugging Face, the open source AI experts. Open source AI is generally better than closed models like GPT, because their impact is measurable. Furthermore, you’ll find here several models that can meet your meet your homework/email/presentation-writing needs whilst consuming 30-60x less energy than bigger LLMs.
HuggingChat lets you choose from a selection of said models:
Inside HuggingChat, right at the bottom of the page, choose the right model for your needs:
- As a rule of thumb, the less parameters, the less energy used. So for maximum frugality on HuggingChat, choose Hermes 3 (8 billion parameters, or “B”) or Phi-4 (15B, even tho it doesn’t say so!) And hopefully, maybe one day Hugging Face’s own smolLM models will be integrated in HuggingChat too…
- To the above point about data centres, think about where the models are hosted: if it’s in France (where Mistral AI runs many of its workloads) versus the USA (GAFAM), emissions are most likely significantly lower, thanks to lower-carbon electricity
- Watch out for reasoning & Master of Experts (MoE) models: whilst Qwen3 is highly recommended and only has 22B active parameters, it ‘thinks’ about its answer before presenting it to you. This ‘thinking’ stage can use up extra energy vs. standard LLMs (87% more in some cases – more on that via Scott Chamberlin, here)
- Test and learn! You may just find that smaller models meet your homework/email/presentation-writing needs just as well as the largest ones (hint: they can!) & as you’re no longer using a bazooka to swat a fly, 🌍 will thank you for it…
- Enjoy! 🤖
2. Prompting
Just as smaller models with less parameters use less energy, so do shorter responses. Why? Generative AI models are essentially probability machines, which calculate the probability of one word coming after the previous one. Each word comprises of one to several tokens. And the calculation behind each token uses energy.
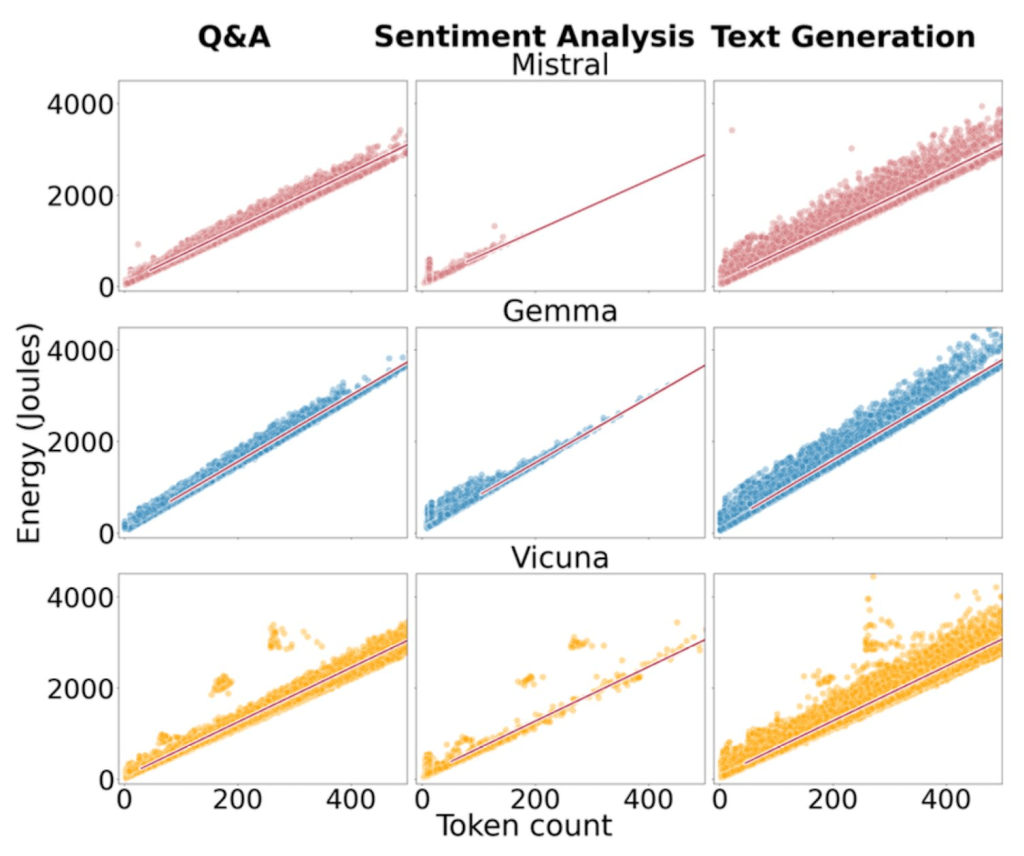
“Green Prompting“, a recent white paper from the UK’s Lancaster University, tested the energy costs of 3 different types of AI usage – Q&A, sentiment analysis and text generation – across 3 different open source models, all with 7 billion parameters each. They found that:
- Response length is one of the most significant factors influencing energy consumption during LLM inference (cf. graph) – indeed, as Adrien Banse, a key contributor to AI energy-monitoring project GenAI Impact confirms, a response that’s 2x shorter will use 2x less tokens, and hence energy
- Prompt length, however, seems to make little difference to energy usage
- Word choice also makes a difference: “analyse” and “explain” use more energy across all models, whereas “classify” tends to use less. That said, the paper’s authors stress this topic requires further investigation.
So what are the key tips for more frugal prompting?
💡 Be concise… literally! End each prompt with “Be concise” to get shorter responses, advises Banse
💡 Be specific: make sure your prompt covers everything you want to know. Any follow-up questions will use more energy*
💡 Be precise: don’t ask AI for the answer to life, the universe and everything! 🤓 Ambiguous requests can make a model search its entire knowledge base, instead of just specific parts of it.*
*Thanks to GreenPT‘s Robert Keus & Cas Burggraaf for these last two tips; looking forward to more soon!
Indeed, it’s too soon yet to say to what degree frugal AI prompting can save energy vs. using smaller models, or data centers with cleaner energy. But, as with the choice of using smaller models, every little helps… and getting your required answer in one go rather than several is way more efficient anyway.
So next time: think before you prompt, and you’ll get what you want… with less impact! 🌍 🤖
